Building tsatu.rocks

Earlier this week I publicly shared my recent side and passion project: tsatu.rocks! TSATU == The Seen And The Unseen. Let's look at how I built it.
Excited to (re)share a side-project I've been working on.
— Diwaker (@diwakergupta) October 1, 2025
Presenting: https://t.co/XZR8Id9GKt !
It's my love letter to The Seen And The Unseen podcast by Amit Varma (@amitvarma)
In each episode, Amit asks his guests to recommend books, music, movies etc and I've discovered… pic.twitter.com/QAZZZKsJL5
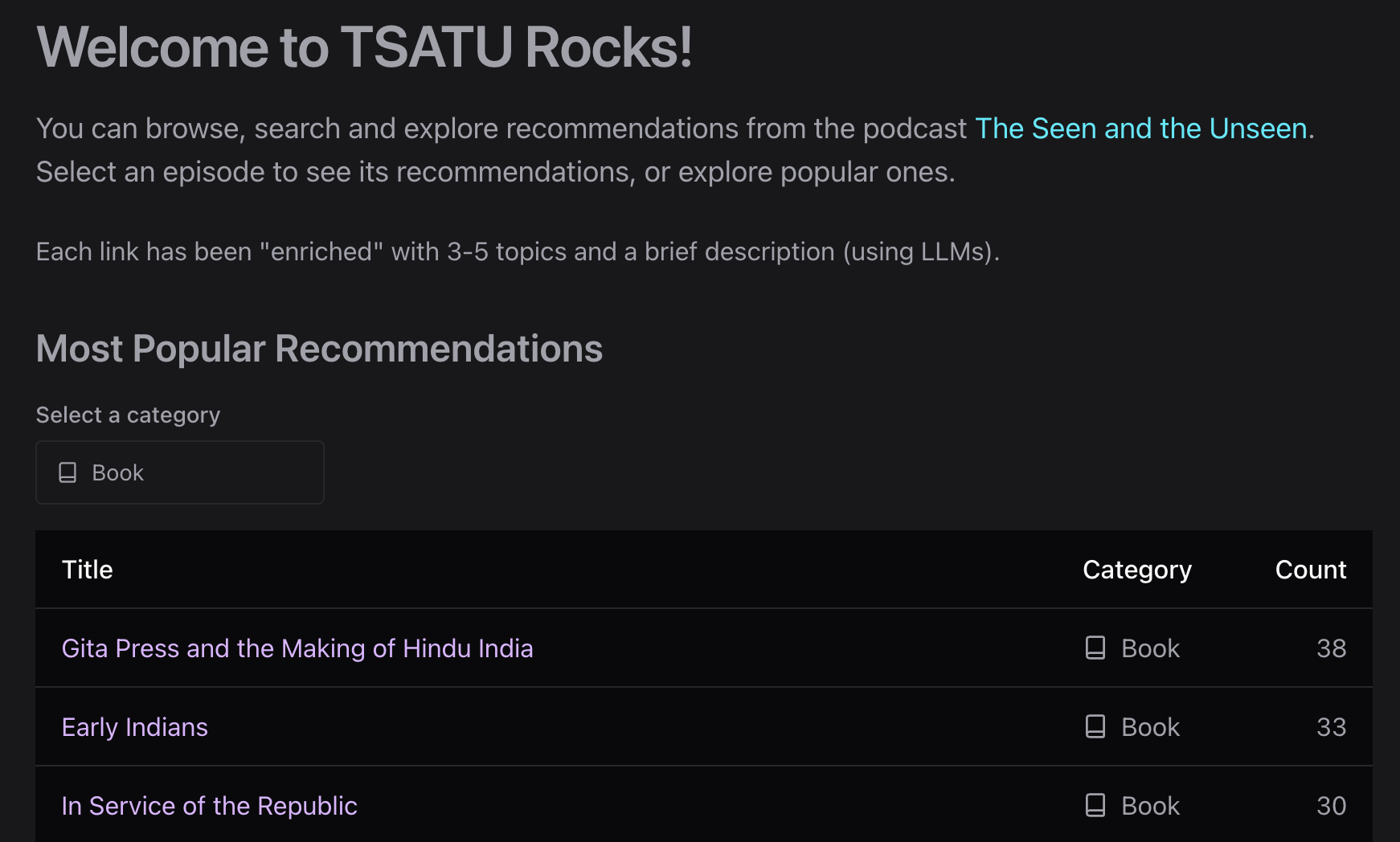
📜 Context
I built an initial version of tsatu.rocks almost exactly a year ago. Pretty simple architecture: sqlite for storage, API endpoints built with go-chi, static vanilla HTML + Alpine.js for talking to the API, Bulma CSS for styling.
In an earlier post I talked about my new "full stack" stack, and this was a perfect project to test that out on! Specifically, the previous app was split across two repos (one for the API and one for the front-end) and I wanted to rebuild it as a mono-repo, partly because having the full stack in a single repo makes the LLMs a lot more effective.
I used AI tools extensively during the re-write. I would say 80% vibe-coded, 20% hand-crafted. My general workflow was:
- create an initial MVP using Codex
- iterate on that using Gemini 2.5 within Zed
📚 Data Gathering
- The server starts by download the podcast RSS feed. It's a big file (10+ MB) so the server downloads it only if there's no local copy or the local version is more than a week old.
- Next, it parses the RSS using
feedsmith. An earlier version used feed-parser, but it didn't support some Apple-specific tags (specifically,itunes:duration), which was a blocker for me. - The above process returns a
feedobject, withitems representing each episode. The most critical field for our purposes is the itemdescription, which contains the show notes. With this in hand, we can move on to the storage layer.
💾 Storage
- tsatu.rocks uses vanilla sqlite for the backend, using Bun's built-in sqlite driver.
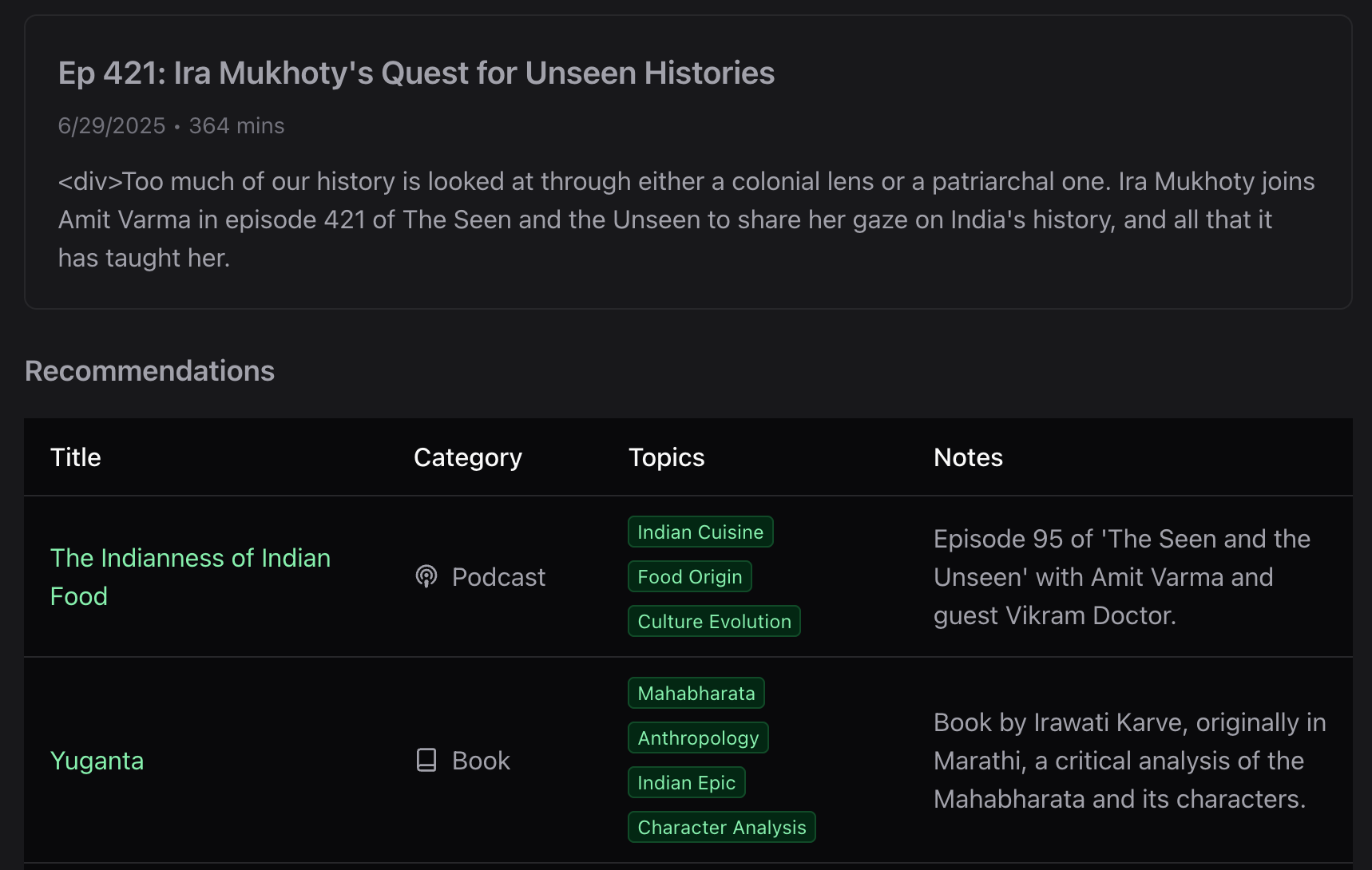
- The schema is pretty straight-forward. 3 tables: one for episodes, one for links (extracted from show notes) and a recommendations table to map which links were recommended in which episode.
- Main challenge here is dealing with inconsistencies in the RSS feed / show notes. For instance, I use a regex to extract the episode number, but not all episodes titles are the same. Example: Episode 404 w/ Devdutt Patnaik is a marathon 12+ hours and actually appears in the RSS feed thrice: once as the full episode, but then again as part 1 / part 2 of ~6 hrs each.
- Another challenge is deduplicating recommendations: the same book or movie or podcast might be referenced using distinct links in the show notes. For instance, a book might be linked to Amazon US in one episode, Amazon India in another episode, Kindle edition in one episode and paperback in another etc. Ditto for titles (e.g. "Rag Darbari" vs "Raag Darbari"). Right now I have a very naive dedup check: first check if the title matches, next check if the URL matches – if either is a match, it's a duplicate.
- A related challenge is getting accurate titles for things. For instance, sometimes the show notes would link the Hindi translation of a book as simply "Hindi", or link to an album would be titled "Spotify". The current implementation checks for such "generic" titles and replaces them with a placeholder title (literally
PLACEHOLDER-<suffix>), and these are updated by the "enrichment" job (more on that later). - Finally, during this process the server categorizes links in one of the following: Book, Author, Artist, Article, Podcast, Music, Video, Social, Newsletter and Generic. This initial categorization is pretty naive, it simply looks for some keywords in the URL: "spotify" for music, "amazon"/"amzn"/"goodreads" for books and so on.
- So at the end of this process we have our 3 tables populated. The import process runs periodically (currently set to once a week, which is fine for TSATU which is now on a two week cadence).
✳️ API
Once the sqlite DB is setup, the APIs themselves were pretty straight forward. Right now I have 3 API endpoints, roughly corresponding to the key features in the app:
- get recommendations by episode
- get popular recommendations (accepts an optional category)
- get search results for a query (more on search later)
The endpoints are implemented as routes in Bun.serve and all of them return JSON.
🎨 Front-end
The UI is built entirely using Chakra components. The Chakra MCP server was very helpful during development. I'm using Lucide icons via react-icons. The UX evolved iteratively as I added features:
- initial version was a single home page with two "tabs" – one for popular recommendations and another for recommendations by episode. Latter had a search box to input the episode number.
- then I added a search box above the tabs, and results were shown below the search box.
- this started to feel cluttered, so I moved the search box to the nav bar in the header. But that didn't look great either, so I eventually moved search to a modal, triggered by
Cmd+K. - I also moved each section – popular recommendations, recommendations per episode and about – to it's own "page". Routing is implemented entirely client side.
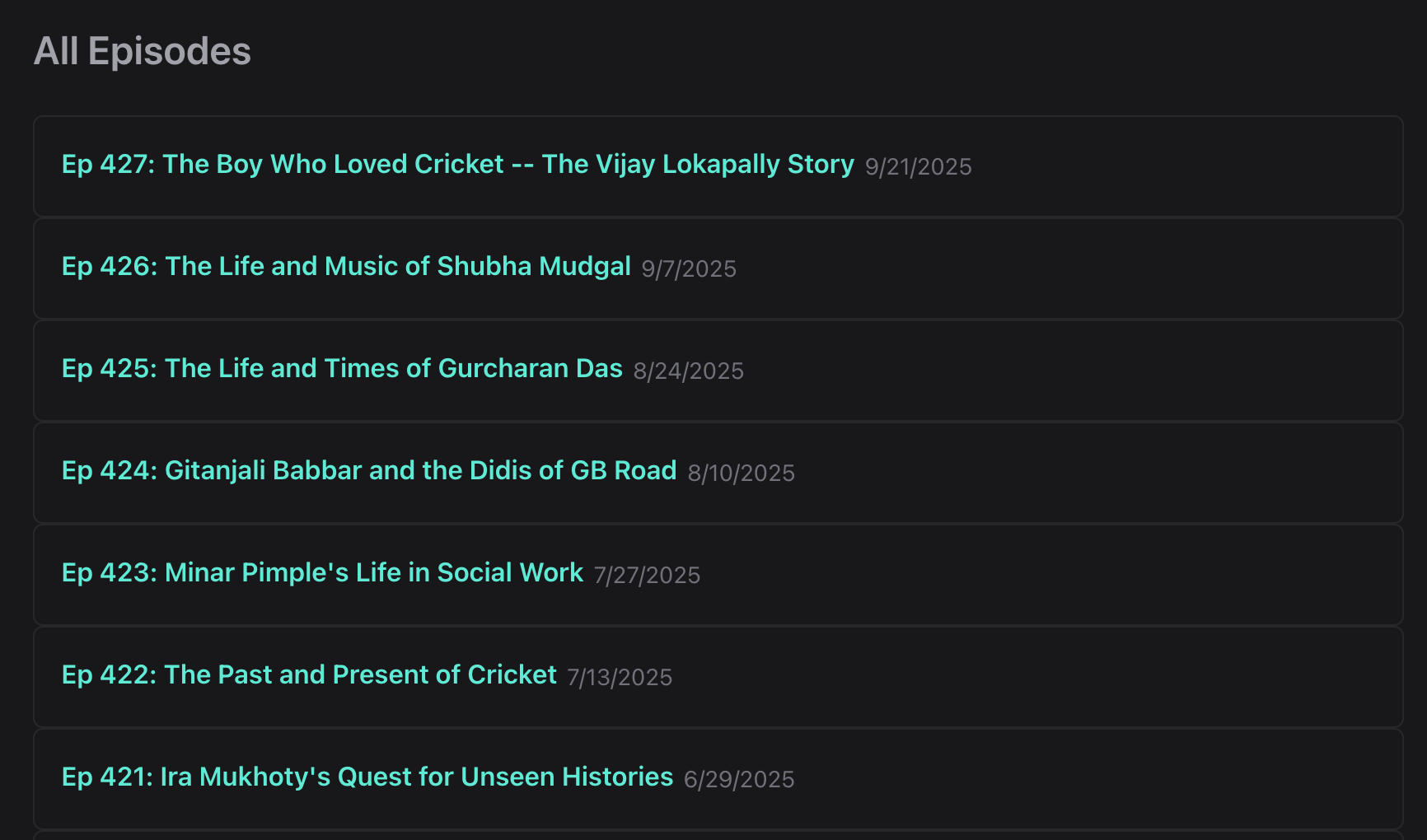
- Finally, I added share-able URLs for search results (example), recommendations per episode (e.g. https://tsatu.rocks/episode/418) and a list of all episodes (in lieu of manually inputting episode numbers). I figured this would improve discoverability.
🔍 Search
After exploring a few different options – from entirely client side search (using something like fuse.js to a dedicated service like typesense) – I settled on sqlite's built-in full-text search capability.
The current implementation searches over: episode titles, all recommendations, enriched topics & notes (see below). The search API endpoint currently returns 25 results, ordered by rank and also includes a snippet of the context the result was found in.
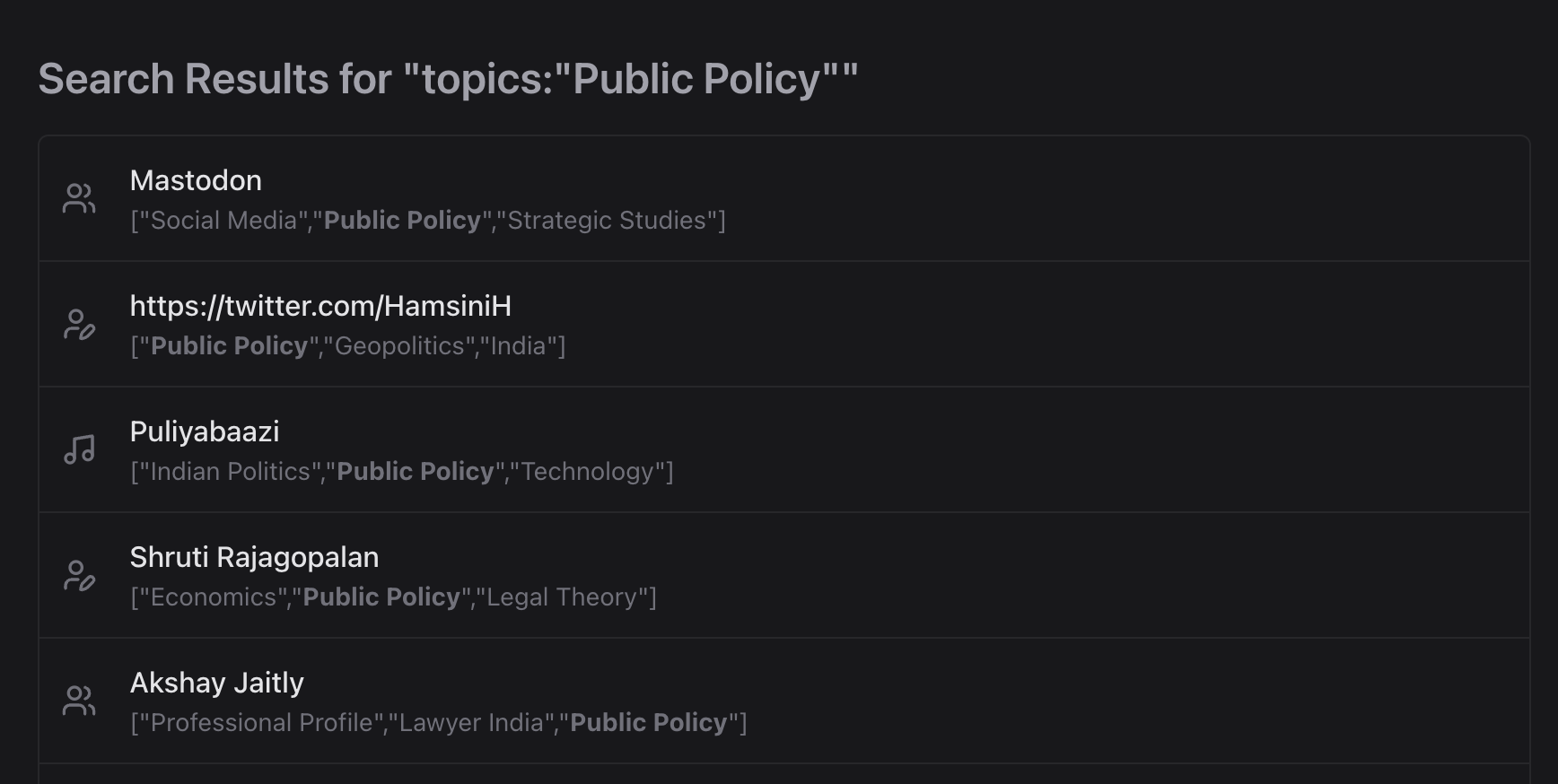
A neat benefit of using sqlite FTS is that a lot of advanced search queries are supported out of the box: phrases, boolean operators, prefix / wildcard search, "near" queries and search in specific columns.
✨ Link Enrichment
While vibe-coding was definitely one of the goals of this project, I also wanted to explore building some AI-powered functionality as well.
One idea I've had for a while is to make the recommendations more searchable and discoverable. For instance, could I search for all books about a given topic, say "public policy" or "economics". LLMs seemed like the perfect use-case for this. Another thought was to use LLMs to improve link categorization and titles. Remember the PLACEHOLDER titles from earlier? Could I leverage LLMs to provide more accurate titles when one was not available in the show notes?
Took me quite a bit of trial and error before I got it all working. Here are just a few things I encountered. I should preface that I focused exclusively on the Gemini API, but I imagine similar issues with OpenAI or others.
- my first naive prompt just provided the title / url from the show notes and asked for topics and additional context (e.g. if the LLM thought it was a URL for a book, return the book author and publication date). Wild hallucinations ensued!
- the next obvious step was to try grounding with web search. This mostly addressed the hallucinations, but then I discovered that you can't get structured output when tool use (like web search) is enabled 🤷
- separately, I discovered the URL context tool in Gemini API, which sounded very promising. But there was a lot of inconsistencies in responses across models (e.g.
flashvs.flash-lite), model often failing to fetch the URL etc - because my use-case doesn't require instant or in-line responses, I briefly explored using the Batch API as well. But ultimately decided it was overkill for now
My final configuration looks something like this:
- Use url context + web search grounding, using
gemini-latest-flash - Provide 10 URLs at a time. Limit is 20, but I kept running into issues where even with 20 URLs sometimes the request would fail complaining that there were more than 20 URLs 🤷
- Since I could use structured output, I just ask the model VERY FIRMLY 😅 to output a JSON object and nothing else. This mostly seems to work.
It takes several hours to enrich the ~9K URLs, but since this mostly one-time processing, it works for me. Being able to test out prompts in AI Studio was super helpful during this process.
🎉 Tada!
So there you have it, pretty pleased with how it turned out!
Bonus: as a finishing touch, I had ChatGPT make me an SVG logo for the site. Took many iterations but I like where I ended: the diamond shape evokes "rock" and the iceberg metaphor gels well with The Seen And The Unseen theme.
Enjoy!